.svg)








Qwen 3.7 is only a day-old, but it’s already being called “unreal”, “incredible”, and even probable “New OS King” on X.com. Two preview models, Qwen3.7-Max-Preview and Qwen3.7-Plus-Preview, landed on LM Arena and immediately placed in the global top 15 for text. Qwen3.7-Max-Preview reached Elo 1,475, ranking 13th overall, 7th in math, and 9th in software/IT tasks.
We went through public data and benchmarks, even ran our own test – Tetris bot self-improvement across 10 iterations, three models, same task – all to find out what puts new Qwen 3.7 ahead of Gemini 3.5 Flash and in the same bracket as Claude Opus 4.7 and GPT-5.5. Looking ahead, it’s quite impressive.
Full breakdown below: what changed in Qwen 3.7, what the Qwen 3.7 benchmarks actually show, how it compares to Claude and GPT-5.5, and how to run Qwen 3.7 right now.
What's New in Qwen 3.7
Qwen3.7-Max is a proprietary reasoning model, available via API only. It's designed as a foundation for agents with long-horizon tasks: where the model needs to maintain context and execute across dozens of steps without losing the thread.
Context window: 1M tokens (up from 256K in Qwen 3.6 Max Preview). It supports 1,000+ tools in agent workflows , with good transfer across common agent frameworks like Claude Code, OpenClaw, Hermes Agent, Qwen Code, and custom tool‑use stacks.
Qwen3.7-Plus leans toward multimodal — it handles image input and is expected to follow the same Apache 2.0 open-weight release path as Qwen 3.6 Plus, likely, in June 2026.
The biggest architectural change: reasoning is on by default – both models require "thinking mode" enabled for peak performance. Earlier Qwen versions treated extended chain-of-thought as optional. Qwen 3.7 treats it as the default inference path.
This mostly means we get more stable, step‑by‑step reasoning out of the box, but will pay for it with slightly higher latency and token usage compared to earlier Qwen versions.
Qwen 3.7 benchmarks: what the numbers show
Alibaba Qwen 3.7: Performance Benchmarks
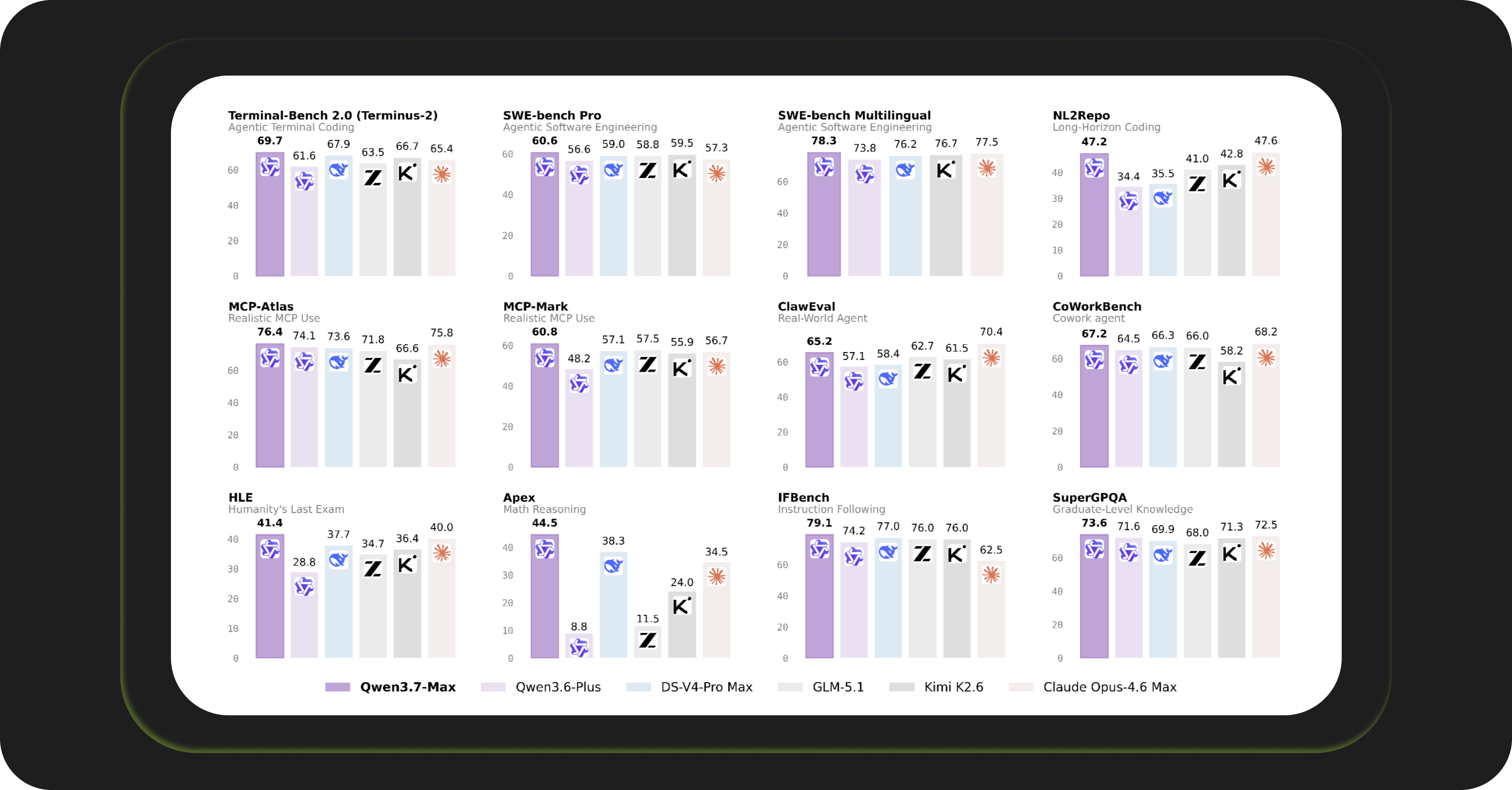
In short, that’s what matters in these numbers:
- Claude is no longer clearly ahead on coding. On SWE-bench Verified, Qwen 3.7 Max (80.4) and Claude Opus 4.6 (80.8) are effectively tied. On SWE-bench Pro, Qwen pulls ahead at 60.6 vs 56.6.
- Training targeted at real agent harnesses. Qwen 3.7 was trained with OpenClaw and Hermes agent harnesses (the same scaffolds used by Atomic Bot) so strong scores there reflect deliberate optimization for these kinds of agent setups, not a lucky accident.
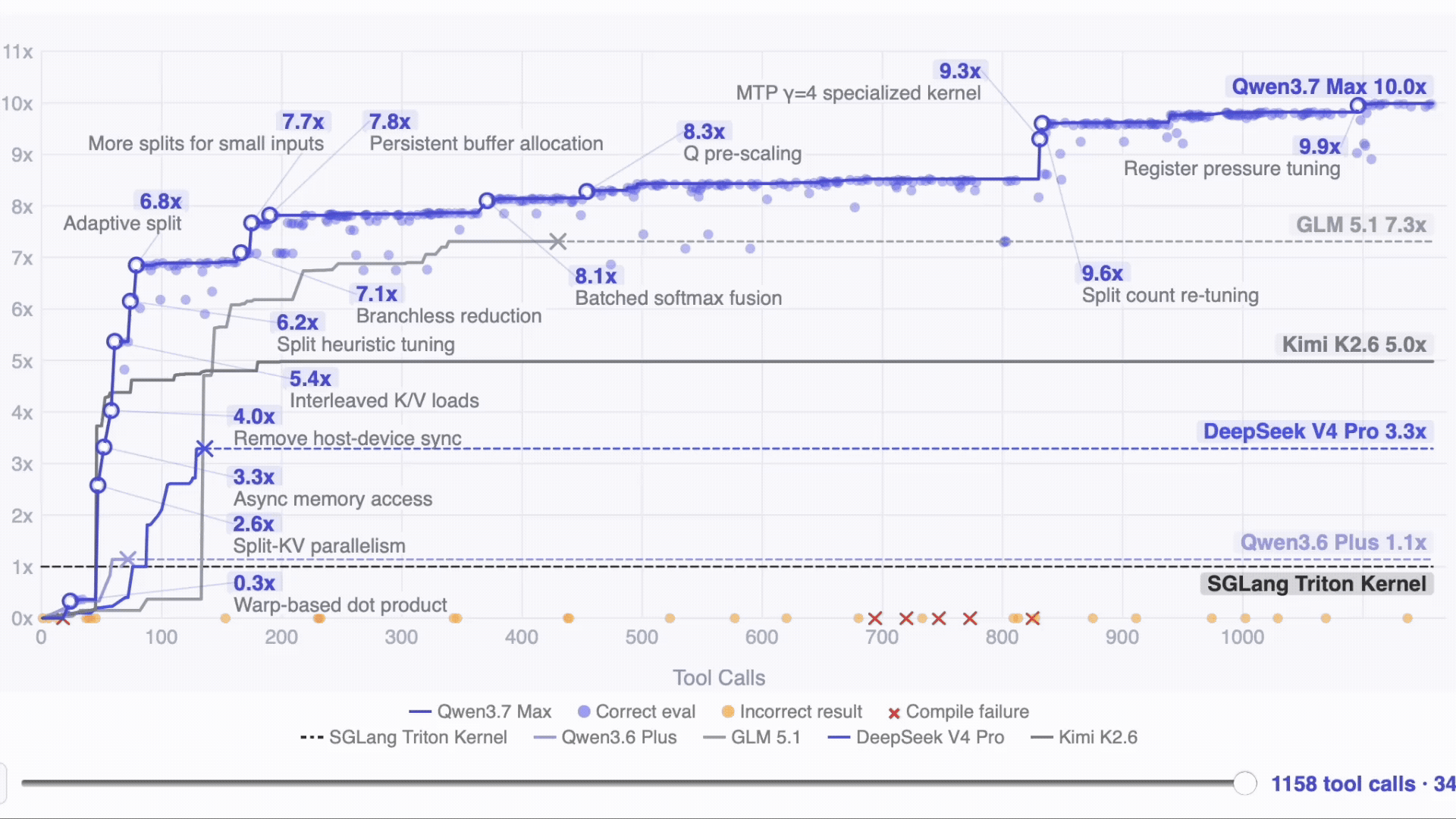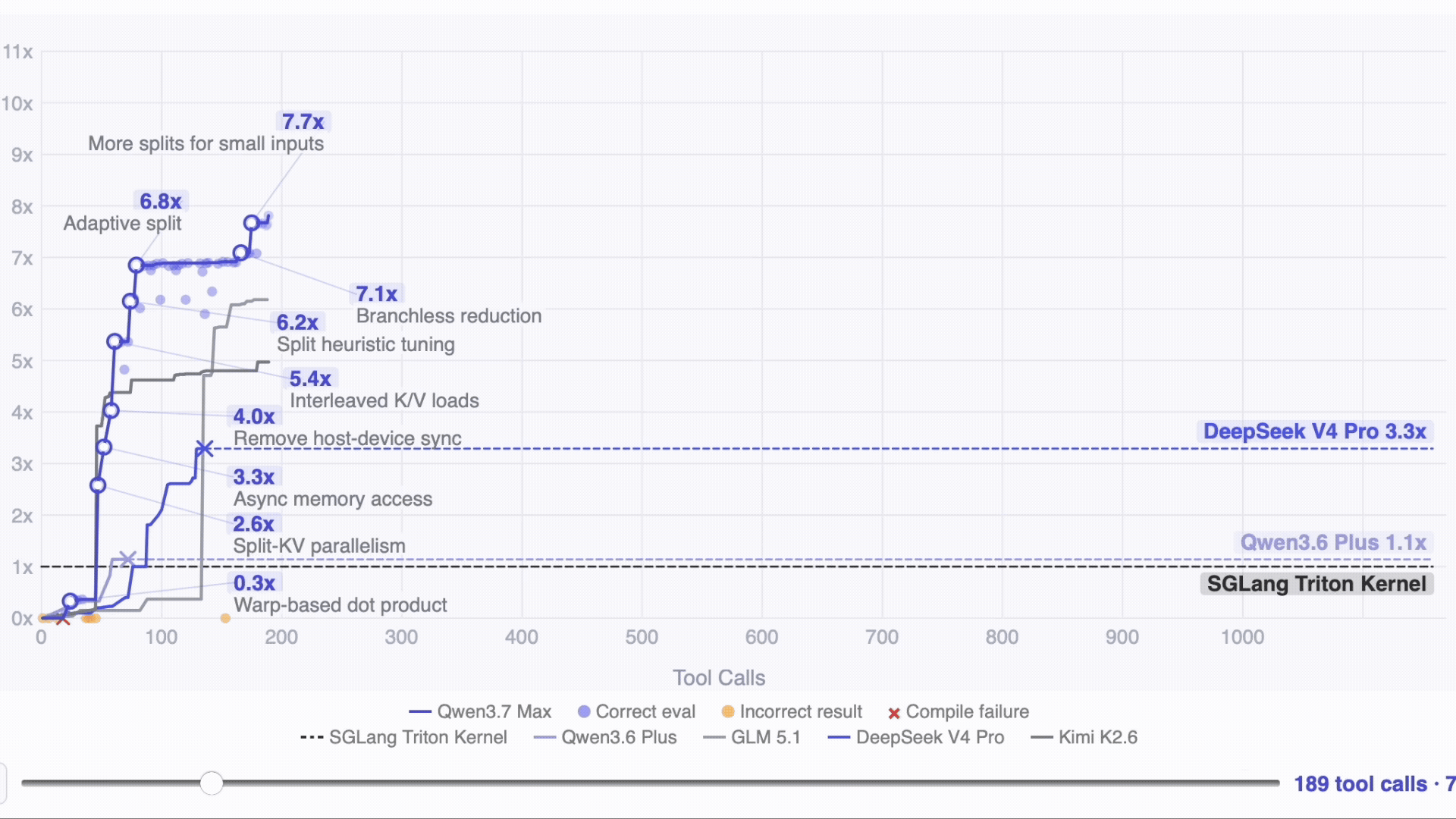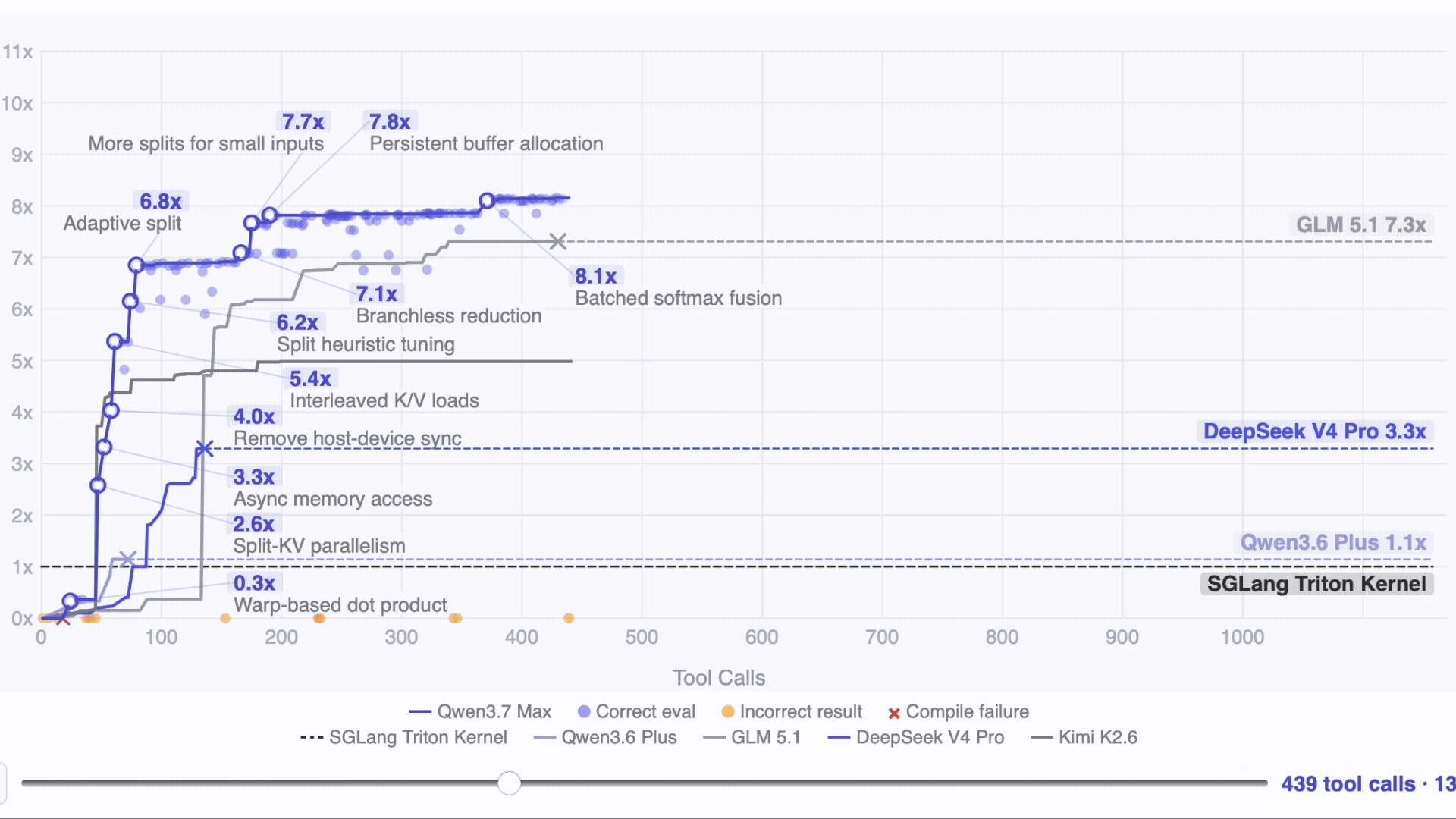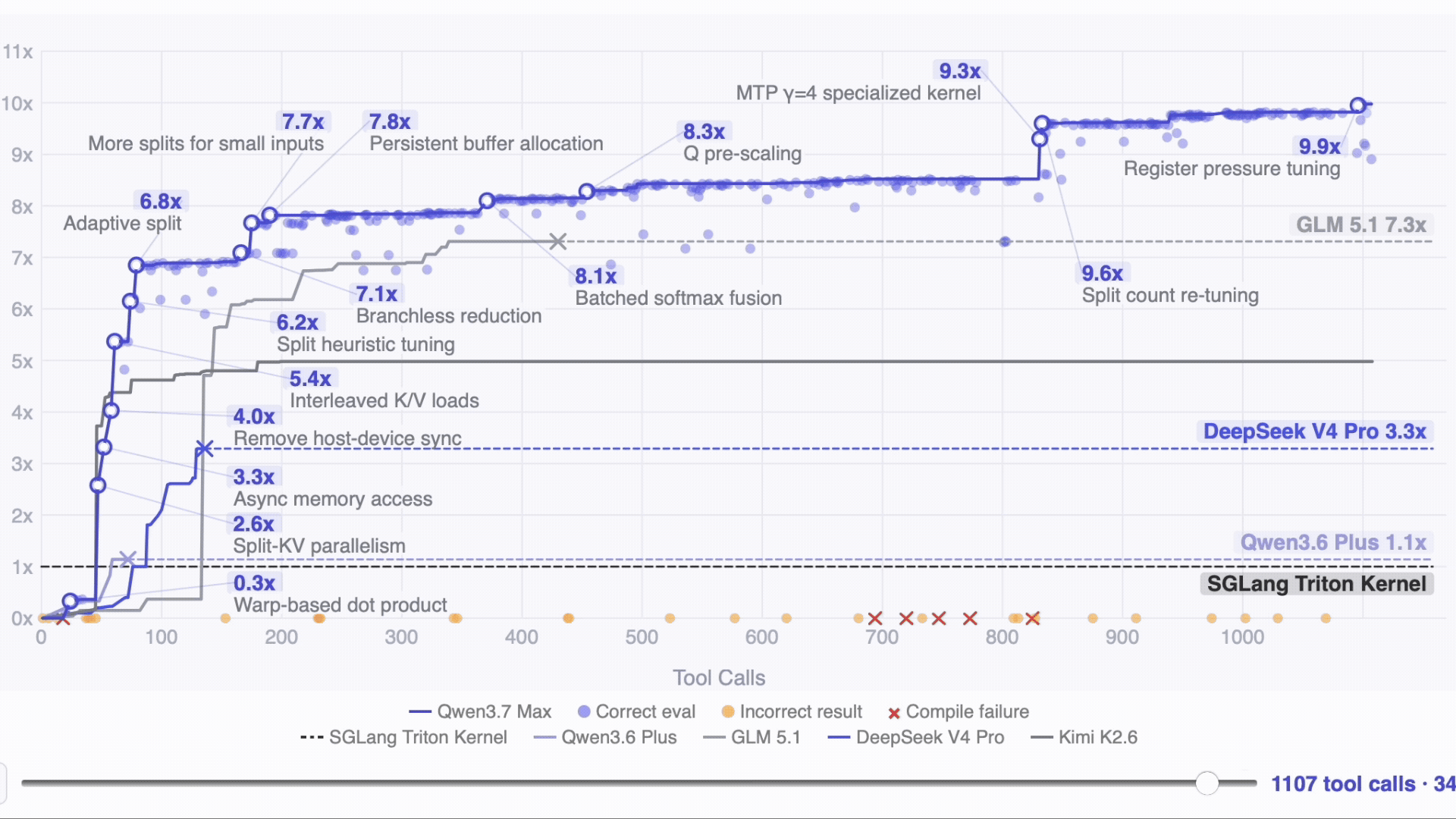
- The 35‑hour kernel run stands out. On unfamiliar hardware with no documentation, Qwen3.7‑Max ran 1,158 tool calls on its own and achieved a 10× speedup on the SGLang Extend Attention kernel, while competitors stopped around 3–7× or failed to converge.
- The context window increase from 256K to 1M tokens is a practical change for long‑running agents that need to keep large codebases or long session histories in memory, rather than just a headline spec.
Diving deeper in Alibaba’s benchmark:
Let’s break down some of the most important indicators in a reader‑friendly way to understand what these numbers actually mean.
Terminal-Bench 2.0: 69.7
Terminal-Bench 2.0 tests how well a model operates inside a real terminal environment: running shell commands, reading output, handling errors, and making decisions over multiple steps. Tasks are run on real machines with a five‑hour timeout, not in a toy simulator.
Reader-friendly version: if you rely on a model to run scripts, automate CLI workflows, or manage servers, this is the most relevant benchmark. Qwen 3.7 Max scores above DeepSeek V4 Pro and clearly beats the previous Qwen generation here.
MCP-Atlas: 76.4
MCP-Atlas measures realistic tool use via the Model Context Protocol. It’s a standard that lets models connect to external services such as search, databases, APIs, and file systems. Tasks are judged by a separate model on whether the agent actually completes the goal, not just whether it prints plausible text.
For you: this matters if you hook your model up to real tools: Slack, email, calendar, search, internal APIs. Qwen 3.7 Max (76.4) comes in slightly ahead of Claude Opus 4.6 (75.8). The difference is small, but Qwen runs at a lower cost per call.
MCP-Mark: 60.8
MCP-Mark focuses on end‑to‑end developer workflows: reading codebases, opening issues, and navigating pull requests through the real GitHub API.
Relevant if you use agents for code review, issue triage, or repository management. Qwen 3.7 Max leads the tested models on this benchmark by more than three points.
CoWorkBench: 67.2
CoWorkBench looks at long, multi‑step desktop productivity tasks: synthesizing documents, running data analysis, formatting reports, and jumping between applications. Tasks cover domains such as computer science, finance, law, and medicine.
If you want an agent to handle everyday “office work” — summarizing research, filling in spreadsheets, producing client‑ready docs — Qwen 3.7 Max currently sits at the top of this benchmark.
ClawEval: 65.2
ClawEval checks whether a model actually completes goals that a real user would care about, across a broad mix of domains.
For you: treat this as a general “can it actually get useful things done?” score. Qwen 3.7 Max scores above Claude Opus 4.6 (62.7) and Kimi K2.6 (61.5). The gap isn’t huge, but it’s consistent with the pattern you see on other agent benchmarks.
HLE — Humanity’s Last Exam: 41.4
HLE is a collection of very hard questions across math, science, law, and other expert domains. A score around 40% looks low in absolute terms, but most models sit below 20%. Crossing 40% puts you near the frontier.
For you: this benchmark matters less for routine tasks and more for research automation, legal analysis, and other work where edge‑case accuracy is critical. Qwen 3.7 Max (41.4) slightly beats Claude (40.0) and has a more noticeable lead over Kimi K2.6 (36.4).
Some more worth-knowing Qwen 3.7 improvements:
1) Qwen has effectively caught up with Claude on coding benchmarks and pulls ahead on some of the harder tasks. On SWE-bench Verified, Qwen 3.7 Max (80.4) and Claude Opus 4.6 Max (80.8) are within 0.4 points, so they are essentially tied. On SWE-bench Pro, Qwen leads at 60.6 vs 56.6, and on SWE-Multilingual it also comes out ahead with a score of 78.3.
2) The model keeps getting better as training data grows. As training environments increased from ~500 to 8,500+, Qwen3.7-Max kept improving, finishing at rank ~3 overall, above Claude Opus 4.6, DeepSeek V4 Pro, and GLM-5.1. Most frontier models plateau well before this point.
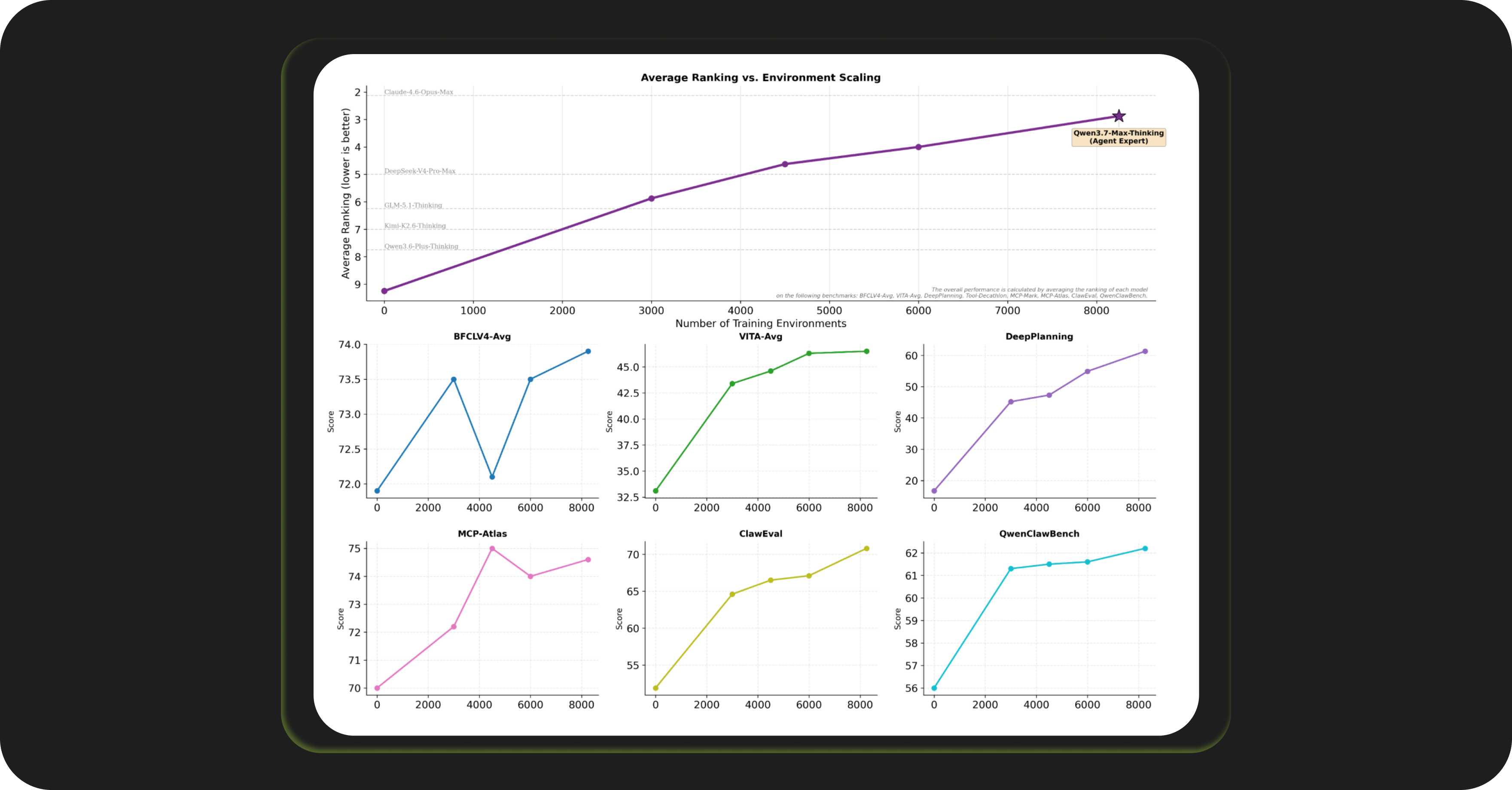
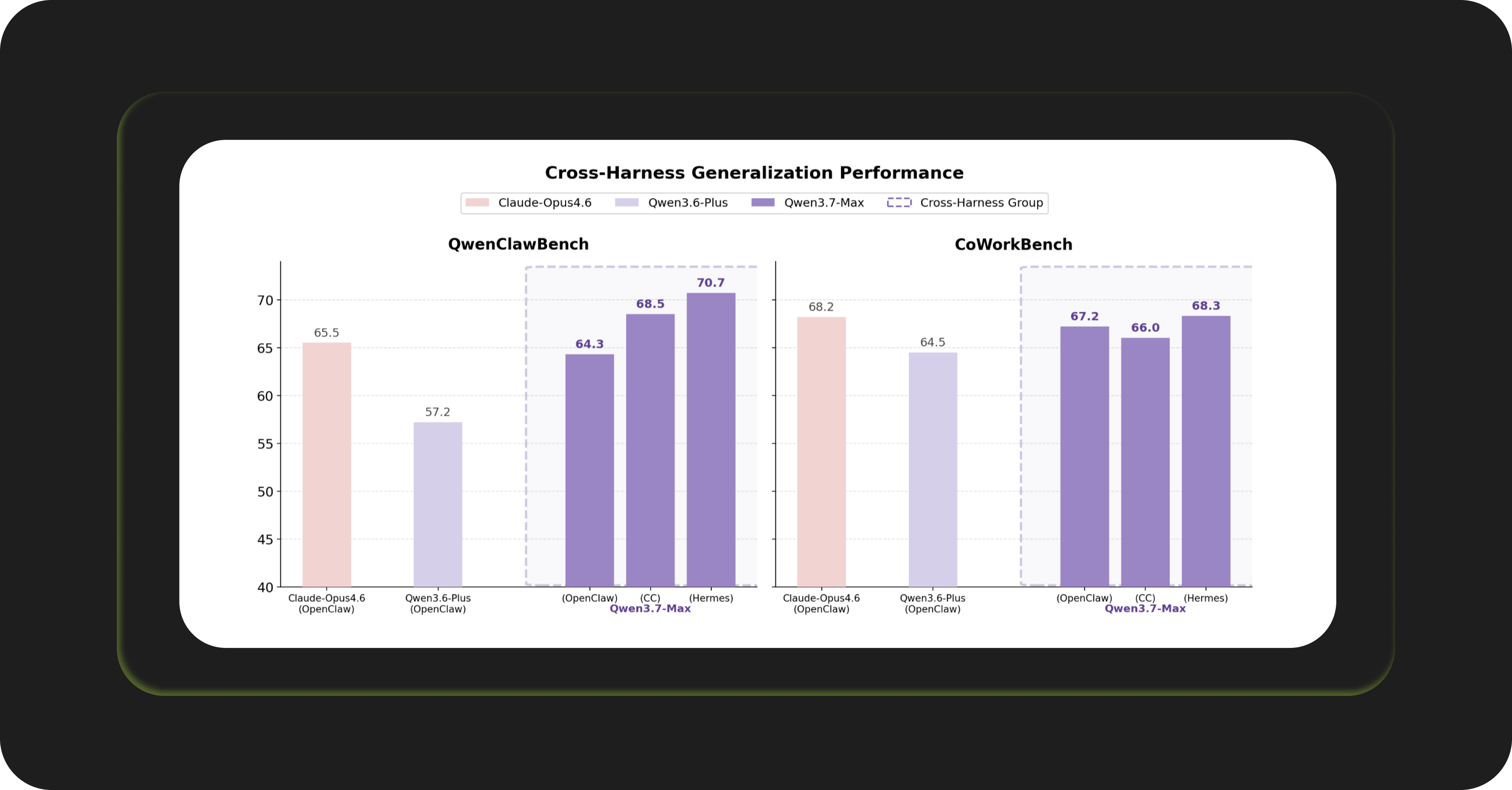
3) It works well across different agent frameworks: Qwen3.7-Max was tested on OpenClaw, CC, and Hermes. On QwenClawBench with the Hermes harness: 70.7 vs Claude Opus 4.6 at 65.5. On CoWorkBench with OpenClaw: 67.2 vs Claude at 68.2 (near parity; Qwen wins on Hermes at 68.3 vs 68.2).
Given completely unfamiliar hardware and no docs, the model kept working autonomously for 35 hours and got 10x further than the competitors. The task: to optimize the SGLang Extend Attention kernel on T-Head ZW-M890 PPUs the model had never seen in training. No prior profiling data, no documentation. Just the existing code and an evaluation script.
After 1,158 tool calls and 432 kernel evaluations across ~35 hours, Qwen3.7-Max reached a 10.0x geometric mean speedup over the Triton reference. GLM 5.1 reached 7.3x. Kimi K2.6 reached 5.0x. DeepSeek V4 Pro reached 3.3x. Qwen3.6-Plus reached 1.1x. Models that stopped early did so because they issued no tool calls for five consecutive rounds — the model concluded it couldn't improve further.
Qwen 3.7 vs Claude Opus 4.6 vs GPT-5.5: self‑directed agent task
We also wanted a simple, reproducible task to see how Qwen 3.7 Max behaves as a self‑directed agent and whether its price advantage over Claude and GPT‑5.5 shows up in a realistic loop. So we set up a small experiment.
Three top‑tier models, the same starting conditions, and no human intervention. Each model had to build a Tetris bot from scratch, then read its own code, run performance benchmarks, and iteratively rewrite itself over 10 iterations.
The aim was to measure how much useful improvement you get for each dollar spent, since costs add up quickly in long‑running agent loops.
Qwen 3.7 vs Claude Opus 4.6 vs GPT-5.5: the result
Qwen won on every dimension - biggest jump, 9x cheaper than Claude, 2x cheaper than GPT-5.5. Long agentic loops is where Qwen Max actually delivers.
Speaking of GPT-5.5 costs, it also burns 10x more tokens than Nemotron 3 Ultra on equivalent tasks.
How to run Qwen 3.7 right now
The current status (May 2026): Qwen3.7-Max weights are not on Hugging Face. No GGUF, no Ollama support, no local run. API only, through Alibaba Cloud Model Studio.
What works today:
- Free preview at chat.qwen.ai: enable "thinking mode" in settings
- API access via Alibaba Cloud Model Studio (rolling out; free during preview)
- Wait for open weights: Qwen3.7-Plus is expected Apache 2.0 in June 2026, same pattern as Qwen 3.6 Plus
If you need a strong local Qwen model right now, Qwen 3.6 is fully available: weights on Hugging Face, Ollama support (ollama pull qwen3.6:27b), GGUF quantizations from Q4 to Q8. Runs at 16GB+ VRAM or 32GB+ Apple Silicon unified memory.
When Qwen 3.7-Plus open weights drop, the setup to run Qwen 3.7 locally will be identical: pull the model via Ollama, connect to Atomic Bot, and you have a fully local agent.
FAQ
Is Qwen 3.7 available for free?
During the preview period (as of May 2026), yes — the API through Alibaba Cloud Model Studio is free, and the chat interface at chat.qwen.ai is also free. Pricing will change when the preview ends. Third-party estimates put output tokens at ~$1.20/M, but Alibaba hasn't confirmed final pricing.
Can I run Qwen 3.7 locally?
Not yet. Qwen3.7-Max weights are proprietary and API-only. Qwen 3.7 open weights (Plus variant) are expected in June 2026 under Apache 2.0 — at which point local runs via Ollama will work the same way as Qwen 3.6 does today. If you need a local Qwen model right now, ollama pull qwen3.6:27b works on 16GB+ VRAM or 32GB+ Apple Silicon.
What is "thinking mode" in Qwen 3.7?
Thinking mode enables extended chain-of-thought reasoning — the model works through a problem step by step before responding, rather than generating an answer directly. In Qwen 3.7, this is required for peak performance (unlike earlier versions where it was optional). Enable it in settings at chat.qwen.ai, or set "reasoning": true in your API config.
What agent frameworks does Qwen 3.7 support?
Alibaba specifically benchmarked Qwen3.7-Max on OpenClaw, Claude Code (CC), and Hermes — three different agent harnesses — and the model performs well across all three. It also supports 1,000+ tools in agent workflows and works with custom tool-use setups without special tuning.
When will Qwen 3.7 open weights be released?
Qwen3.7-Plus open weights are expected in June 2026, following the same Apache 2.0 release pattern as Qwen 3.6 Plus. Qwen3.7-Max is proprietary and will remain API-only.
What to do now
Price is the factor that actually bites currently: Qwen 3.7 Max lands within a few points of GPT‑5.5 and Claude Opus 4.6 on most tests, but its output tokens are about 60× cheaper.
The kernel run is the result worth paying attention to: no documentation, unfamiliar hardware, only the existing code and an evaluation script. Qwen issued 1,158 tool calls across 35 hours and reached a 10x speedup.
If you’re using Atomic Bot, there’s one extra detail to care about. Alibaba trained Qwen 3.7 Max on OpenClaw and Hermes, the same harnesses Atomic Bot uses. It scored 70.7 on QwenClawBench with Hermes, which means that when open weights arrive in June, it's ready to adapt to your stack.
Until those weights ship, you can run Qwen 3.6 locally via Atomic Bot: same Ollama setup, same local agent wiring. Once Qwen 3.7 Plus is released as open weights, switching over should be a matter of a couple of minutes.


