.svg)








This is probably the first model to integrate 1M token context, top-tier performance on coding and multimodal understanding – all in one package.
MiniMax M3 comes in with the cheapest API pricing of the four models and a new sparse attention architecture that claims 15x faster decoding at 1 million token context for long-range Agent tasks, long-range Coding, and long-video understanding.
Is this a sign to drop new Claude Opus 4.8, which is just two-days older?
🎯 TL;DR
What we know about new MiniMax M3 so far:
- MiniMax 3 is the latest frontier model from Chinese MiniMax, built on a new proprietary architecture – MiniMax Sparse Attention (MSA).
- MSA expanded the context window to 1 million tokens (5x jump from MiniMax M2.7), bringing it in line with Claude Opus 4.7 and Gemini 3.1 Pro.
- Price stays the same as M2.7 ($1.20 per 1M input/ $4.80 per 1M output) – efficiency is claimed to be 9.7x faster context reading and 15.6x output generation
- MiniMax 3 exposes an OpenAI-compatible API endpoint, meaning it works out of the box with any tool or agent runner that supports the OpenAI format – including Atomic Bot.
🔗 MiniMax M3 Features
A closer look at some of its most important features:
Open-weight model
M3 is open-weight model, that can be downloaded and run on your own hardware: it gives you choice over how and where they run it. You can self‑host it in your own infrastructure for better data privacy, fine-tune it on your codebase or domain so it behaves more like an in‑house engineer, and optimize costs/latency by choosing your own hardware and quantization strategy.
1M token context window at 1/20th the compute cost
It processes memory in blocks, reading each block once instead of revisiting it repeatedly. At 1 million tokens, M3 uses 1/20th the compute M2.7 needed => processing is 9.7x faster at the start of a request and 15.6x faster when generating output.
The price stays the same, but 20x more efficient: $0.60 input / $2.40 output per million tokens for calls <512K. 512K-1M, the rate is $1.20 input / $4.80 output.
Here’s the comparison of API pricing/1M Tokens among leading frontier-models:
In a nutshell, MiniMax M3 is the least costly model among the most popular frontier models.
A natively multimodal model
Most AI models process visuals as a separate capability layer: it weakens how well a model understands complex documents mixing text and images.
In MiniMax M3 text, images, and video were part of training from step one, so it consistently understands visuals and complex PDFs. They rebuilt the full data pipeline around interleaved multimodal data at 100 trillion tokens.
We ran our test to verify this claim: how MiniMax M3 will turn a napkin sketch into a playable game. We handed MiniMax M3 a hand-drawn draft of a Doodle Jump style platformer, and it read the elements off the draft, wrote the logic, drew the interface and shipped it as one self-contained HTML game.
The result is rather enjoyable:
- Input: 6,920 tokens
- Output: 9,933 tokens
- Total cost: $0.028
High coding and agentic performance
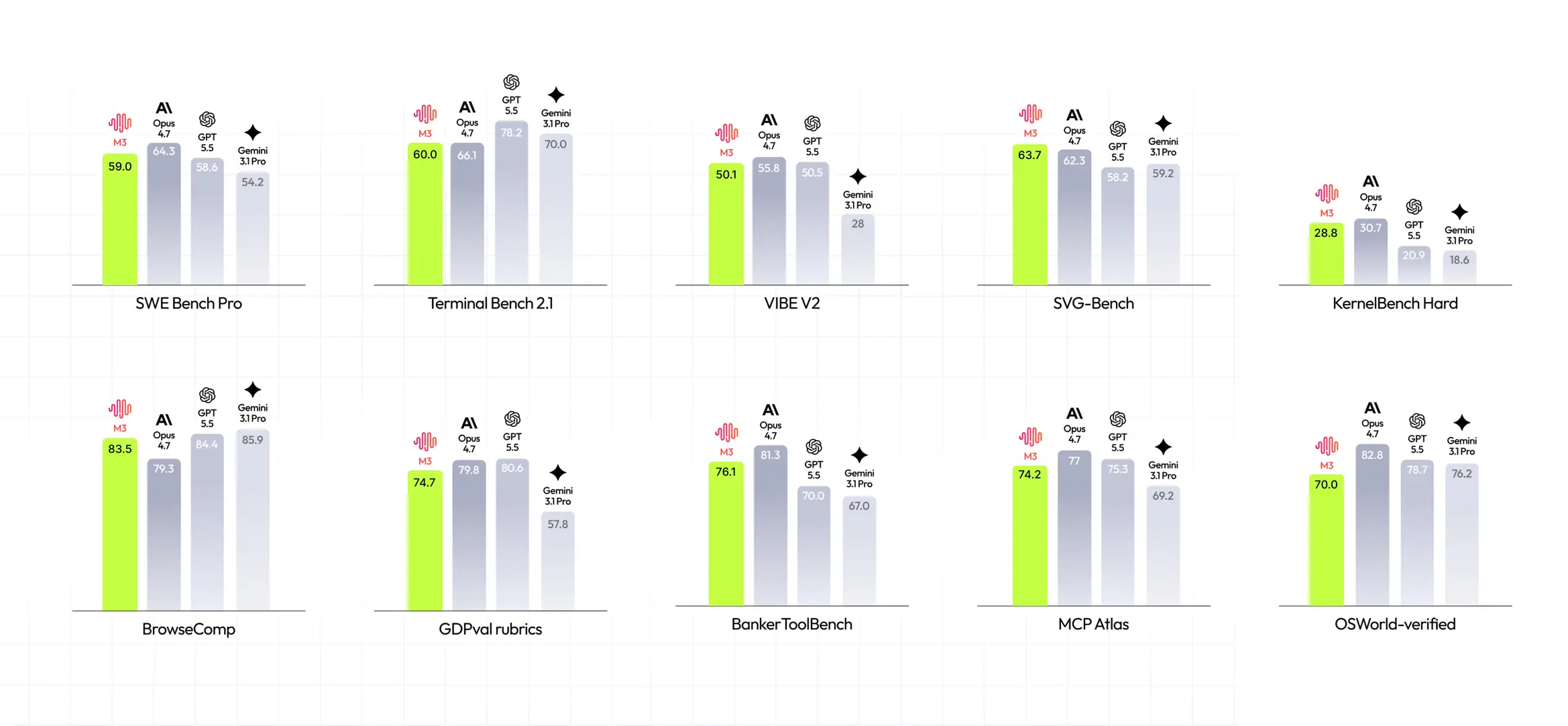
MiniMax M3 is stronger for multi-step agent work than for isolated code generation: M3 at 59.0%, ahead of GPT-5.5 (58.6%) and Gemini 3.1 Pro (54.2%), behind Opus 4.7 (64.3%). Claw-Eval (end-to-end agentic task completion): 74.5, the highest in this group.
Long-horizon autonomous work
The new MiniMax M3 focuses on executing long-horizon tasks. It understands data from the paper, code and experiment logs in a single window, code and executes tasks with agents.
Asked to reproduce an ICLR Outstanding Paper autonomously, M3 ran for 12 hours, produced 18 commits and 23 experimental figures with no control. On a harder problem, CUDA FP8 kernel optimization, with no reference – it ran independently for 24 hours, made 1,959 tool calls, and pushed hardware utilization from 7.6% to 71.3%.
🦀 MiniMax M3 vs Claude Opus 4.7
Important note: MiniMax M3 is two-days older than Claude Opus 4.8. This is why the only reliable benchmark available is MiniMax M3 vs Claude Opus 4.7. If you’re already on Opus 4.8, consider Claude’s output to be less smaller/higher since the gap between Opus 4.8 and 4.7 is not critically wide.
Software engineering tasks: Claude Opus 4.7 is better than MiniMax M3
Claude Opus 4.7 scores 87.6% on SWE-Bench Verified and 64.3% on SWE-Bench Pro. MiniMax M3 scores 80.5% and 59.0% on the same benchmarks. Opus 4.7 leads clearly on both.
On SWE-Bench Pro specifically, MiniMax positions M3 as "surpassing GPT-5.5 and Gemini 3.1 Pro and approaching Opus 4.7." The table confirms this: M3 (59.0%) beats GPT-5.5 (58.6%) and Gemini 3.1 Pro (54.2%), but doesn't close the gap with Opus 4.7 (64.3%).
For coding agents where SWE-Bench performance is your proxy, Opus 4.7 is the better choice, judging by raw SWE‑Bench performance. Though, the cost tradeoff is palpable: Opus 4.7 costs $25/1M output tokens; MiniMax M3 is $2.40/1M at standard context length (≤512K), currently discounted to $1.20 for the first 7 days post-launch.
MiniMax M3 leads on long-horizon agent tasks
In Claw-Eval, an end-to-end evaluation framework for autonomous agents, MiniMax M3 scores 74.5, the highest among all models in the comparison – Opus 4.7 scores 71.6, GPT-5.5 is not scored, Claude Sonnet 4.6 scores 68.3.
M3 was given an FP8 matrix multiplication problem on NVIDIA Hopper GPUs with no reference implementation, no benchmark script, no skeleton that couldn't run yet, and no human interaction. Over 24 hours of continuous autonomous work, M3 ran 147 benchmark submissions and 1,959 tool calls. It improved hardware peak utilization from 7.6% to 71.3%, which is 9.4x.
Most other models stopped making new progress within the first 30 submissions. M3's best solution appeared on submission 145, and Only Opus 4.7 showed similar persistence.
PostTrainBench (autonomous model training across 12 hours): M3 scores 37.1%, Opus 4.7 leads at 42.4%, GPT-5.5 is at 39.3% – M3 places third here, but for price 10x less. For teams running such workloads regularly this 5-point performance gap looks less depressive since the cost is significantly less.
BrowseComp: M3 Ahead of Opus 4.7 on Autonomous Web Research
On BrowseComp, M3 scores 83.52 against Opus 4.7's 79.3: a 4-point lead on tasks requiring to browse the web autonomously to answer complex, multi-step questions.
One methodological note: M3's evaluation discards conversation history when token usage exceeds 64K, which may affect direct comparisons with providers using different token budgets.
Even when Gemini 3.1 Pro and GPT-5.5 enter the competition, the shift isn’t big. They slightly exceed MiniMax M3: Gemini 3.1 Pro – 85.9% (2,38% more than M3), GPT-5.5 – 84.4% (0,88 more). In practice, this is not something that you’ll notice in your daily work.
♊️ MiniMax M3 vs Gemini 3.1 Pro
Agentic work: MiniMax M3 leads
On Claw-Eval (end-to-end autonomous agent tasks), M3 scores 74.5 against Gemini's 57.8: it’s a 17-point gap. In practice, M3 is less likely to stall, lose track of the goal, or require human correction mid-run on long workflows like data collection across multiple sources, or multi-tool business processes.
If your agent reads, writes, or reasons over spreadsheet data (financial reports, operations data, CSVs), M3 is the clear choice for anything data-table-heavy: on SpreadSheetBench, M3 scores 89.35 against Gemini's 56.06. MCP Atlas: M3 at 74.2, Gemini at 69.2.
MiniMac M3 vs Gemini 3.1 Pro in coding: near tie with different edges
On SWE-Bench Verified, the scores are almost identical: M3 at 80.5, Gemini at 80.6. On SWE-Bench Pro (harder, more realistic GitHub issue resolution) M3 leads 59.0% to 54.2%, making it the better choice for complex software engineering tasks: multi-file bugs, implementing features from issue descriptions, or handling large-scale refactors across a codebase.
On Terminal-Bench 2.1, which tests command-line execution and shell-based workflows, Gemini leads 70.3 to 66.0 => pick Gemini if it’s important for you that the model handles shell scripting, build pipelines, dependency management, and CI/CD execution more reliably.
🤖 MiniMax M3 vs GPT-5.5
MiniMax M3 is better for financial simulations
In a YC-Bench, a simulation where an agent manages investment decisions across startup scenarios, M3 scores 2.10M against GPT-5.5's 1.28M: a 64% gap. M3 outperforms GPT-5.5 in tasks, where the agent needs to compare options, apply criteria, and reach a conclusion instead of just retrieving and summarizing, which makes it the perfect model for tasks like investment screening, competitor monitoring, due diligence research, and budget analysis.
GPT-5.5 is better for complex chained agent workflows
In Apex-Agents tests (probably, in one of the sharper differentiators in this comparison): GPT-5.5 scores 41.7%, M3 scores 27.7% — a 14-point gap. This test is about agents that easily coordinate across multiple tools, maintain stability across long task chains, and recover from failures mid-run. If you juggle several agents/tools/LLMs in sequence: GPT-5.5 handles these heavy and versatile workloads more reliably than M3.
This idea can also be pinned by Terminal-Bench 2.1 results: GPT-5.5 at 78.2 vs M3's 66.0 – in doing heavy executions, managing system-level operations GPT-5.5 is still the king, and holds this status among all the models.
🏆 Best Models by Tasks in 2026
Best For Coding Agents: Claude Opus 4.7 or MiniMax M3
Choosing the leader for Codex or OpenCode, it is still Opus 4.7. MiniMax M3 is competitive, but not a first choice. On SWE-Bench Verified (87.6%) and SWE-Bench Pro (64.3%), Opus 4.7 leads the comparison and it’s the strongest model for software engineering agents with clear code generation or bug-fix tasks.
However, the cost difference is serious: $25 vs $2.40 per million output tokens at standard rate. But if your focus is on production code agents where failures are expensive, it's justified. If your budget is tight, and you’re not ready to pay through the nose – MiniMax M3 is still safe.
Best for software development and complex automation: GPT-5.5
GPT-5.5 here scores 82.9% on SWE-Bench Verified – the highest coding quality score in this comparison. On Apex-Agents, which tests complex multi-step agent workflows, it scores 41.7 against M3's 27.7. If your agents write production code, manage software projects, or run orchestrated multi-tool pipelines where failures cascade, GPT-5.5 is the most reliable option here.
For Long-Horizon Agentic Tasks: MiniMax M3 or Opus 4.7
MiniMax M3 doesn’t need to fight for supremacy. This time it shows highest in the comparison score – 74.5% in completing complex, multi-hour autonomous runs. Only Opus 4.7 showed comparable persistence in long-running agent evaluations.
For agents that need to run continuously for hours: research, autonomous code optimization, iterative model training – both M3 and Opus 4.7 are reasonable choices. The dealbreaker for Opus 4.7 is that it is a greedy model – while M3 is significantly cheaper, especially on agents like OpenClaw or Hermes, where Claude Opus 4.7 charge extra tokens (real costs rise up to 25–27%).
Best for business workflows: MiniMax M3
On benchmarks that simulate real business decision-making, M3 leads the group. Investment and startup simulations, financial tool use – M3 is the highest in the comparison. These benchmarks reflect what business agents actually do: analyzing options, working with structured data, executing across financial and operational contexts.
If you strive to automate your sales/finance research and further reports, run M3 on Hermes (if you need to automate repetitive tasks) or OpenClaw (for larger projects).
❓FAQ
Is MiniMax M3 better than Claude Opus 4.7?
Roughly speaking: M3 scores higher on end-to-end agentic evaluation, OmniDocBench multimodal documents. Opus 4.7 leads in coding, GUI agent, and holds better context. But speaking of Opus 4.7 supremacy: the gap in efficiency is not really worth the price if you’re on a budget.
You can still fully rely on M3 (except for heavy coding): it’s cheaper, it’s open-weight (so you can keep your data private).
What is MiniMax Sparse Attention and why does it matter?
MSA is MiniMax's new attention architecture that reduces per-token compute at long context to 1/20th of their previous model. This enables 1M token context at low cost, with 9.7x faster prefill and 15.6x faster decoding versus M2.7. The architecture also matches full attention on most capability benchmarks, meaning the efficiency gain doesn't come with a quality tradeoff.
How does MiniMax M3 compare to MiniMax M2.7?
The coding improvement on SWE-Bench Verified is minimal (79.9 → 80.5). The agentic and long-context improvements are large: LOCA-Bench went from 0 to 49.3, MCP Atlas from 49.4 to 74.2, Claw-Eval from 49.7 to 74.5. M2.7 couldn't meaningfully handle long-context or multi-step agentic tasks. M3 can.
Which 2026 model has the best price-to-performance for API use?
For multimodal document tasks and most agentic pipelines, MiniMax M3 at $0.60/$2.40 per 1M tokens (standard rate) has no close competition on price-to-performance. The caveats: the premium long-context rate above 512K changes the math for very long inputs, and independent latency benchmarks aren't yet published. For pure coding, Opus 4.7 still justifies its price premium on SWE-Bench.
Can I run MiniMax M3 locally with an AI agent runner?
Not yet, but soon you will. MiniMax plans to release open weights around June 11, 2026. Once available, MiniMax M3 can be run locally through Atomic Bot: no API, no per-token cost, data stays on your machine. None of the other models in this comparison offer this.
Bottom line
MiniMax M3 launched one day ago and is already pulling 32 billion tokens per week on OpenRouter. And we can investigate benchmarks all we want and find these slight 2% differences in productivity, the idea stays the same: MiniMax M3 competes with Opus 4.7 and GPT-5.5 on real-world agentic tasks at one of the cheapest conditions – at $0.60 input / $2.40 output per million tokens. And for this price we get unprecedented package: 1M window, 12 hours of autonomous and successful execution and multimodality. For developers who've been waiting for an open-weight model that can handle the same workloads as the closed options, M3 is the first candidate.


